
データパイプラインの自作がもたらす、確かな手応えと新たな視点
データ分析の学びを進める中で、手元の静的なデータだけでなく、現実世界で今まさに動いているデータを扱ってみたいと考える方は多いはずです。
今回は、静岡市が公開しているオープンデータAPI(アンダーパス冠水水位情報)を活用し、データを取得してデータベースに蓄積し、地図上にリアルタイム表示する実践記録をお届けします。
この一連のデータパイプラインをゼロから構築する理知的でスマートなアプローチを、実際のコードと共にご紹介します。自らの手でデータの流れを設計することで、現場の課題解決に直結する生きたスキルが身につきます。
1. データパイプラインの基本構造:「ポンプ・水槽・蛇口」
モダンなデータ活用(ETLプロセス)は、よく水回りのシステムに例えられます。今回のダッシュボードも、この3層構造で設計しました。
まずは「抽出(Extract)」です。これはポンプの役割を果たします。R言語のスクリプトを使って、静岡市のAPIという水源から、現在の水位データを5分おきに汲み上げます。
- Extract(抽出)= ポンプの役割 R(RStudio)のスクリプトを使って、静岡市のAPI(水源)から「今」の水位データを5分おきに汲み上げます。
- Load(格納)= 水槽の役割 汲み上げたデータをGoogle Cloudの「BigQuery」へ送ります。ここにデータを蓄積することで、過去と現在の比較が可能になります。
- Transform & Visualize(変換と可視化)= 蛇口の役割 「Looker Studio」をBigQueryに接続し、蓄積されたデータの中から「最新のデータ」だけを抽出し、見やすく地図上に表示します。
この設計の優れた点は、ダッシュボードを見る人が何千人になろうと、市のサーバーに負荷がかかるのはポンプが動く1回だけという点です。社会インフラのデータを扱う上で、この負荷分散は非常に誠実でスマートなアプローチと言えます。
2. 【コード公開】Rでデータを汲み上げる「ポンプ」の構築
百聞は一見に如かず。実際に私がRStudioで実行している、APIデータの取得からBigQueryへのアップロードまでを完結させるフルスクリプトを公開します。
# 必要なライブラリの読み込み
library(httr)
library(jsonlite)
library(tidyverse)
library(bigrquery)
# 1. 静岡市APIから最新のアンダーパス水位データを取得
url_up <- "https://openapi.city.shizuoka.jp/opendataapi/servicepoint/underpath"
res_up <- GET(url_up)
raw_data <- fromJSON(content(res_up, as = "text", encoding = "UTF-8"))
# 2. データの整形(JSONのネスト構造をバラして表形式にする)
bq_df <- data.frame(
point_name = raw_data$Data$features$properties$observerpointname,
water_level = raw_data$Data$features$properties$waterlevel,
update_at = raw_data$Data$features$properties$updatedate,
road_name = raw_data$Data$features$properties$roadname
) %>%
mutate(
water_level = as.integer(water_level),
update_at = as.POSIXct(update_at) # 時間データとして認識させる
)
# 3. BigQuery への接続とアップロード(追記モード)
project_id <- "あなたのプロジェクトID"
dataset_id <- "shizuoka_opendata"
table_id <- "underpath_levels"
dest_table <- bq_table(project = project_id, dataset = dataset_id, table = table_id)
bigrquery::bq_table_upload(
x = dest_table,
values = bq_df,
write_disposition = "WRITE_APPEND" # データの上書きではなく「蓄積」する
)
print("--- データ送信が完了しました! ---")このコードを実行するだけで、APIの奥深くにある「水位」や「更新日時」といった情報が綺麗な表に整理され、クラウド上の水槽(BigQuery)へと注ぎ込まれます。
3. Looker Studioでの可視化と「データクレンジング」の重要性
BigQueryにデータが届けば、あとはLooker Studioで自由にビジュアライゼーションするだけです。 しかし、ここで実践ならではの壁にぶつかりました。
取得した地点名(例:「柚木」や「大坪」)をそのままGoogleマップにプロットしようとすると、他県にある同名の地名と混同され、ピンが全国へ飛び散ってしまったのです。
そこで、Looker Studio側でひと手間(データクレンジング)を加えました。 「計算フィールド」という機能を使い、地点名に強制的に「静岡市」という文字を結合させたのです。
- 計算式:
CONCAT(point_name, ", 静岡市")
この新しいフィールドを住所データとして地図に適用した瞬間、全てのバブルが静岡市内にピタリと収まりました。生データをそのまま鵜呑みにせず、意図した通りに動くよう微調整する。
このひと手間が、ダッシュボードの信頼性を決定づけます。
圧倒的な行動量が、内発的動機づけを加速させる
コードを書き、データを送り、Looker Studioの画面を更新する。そこに「2026/04/02 6:20:00」という現在の時刻と、リアルタイムのバブルが静岡市の上に浮かび上がった瞬間、えも言われぬ感動を覚えました。
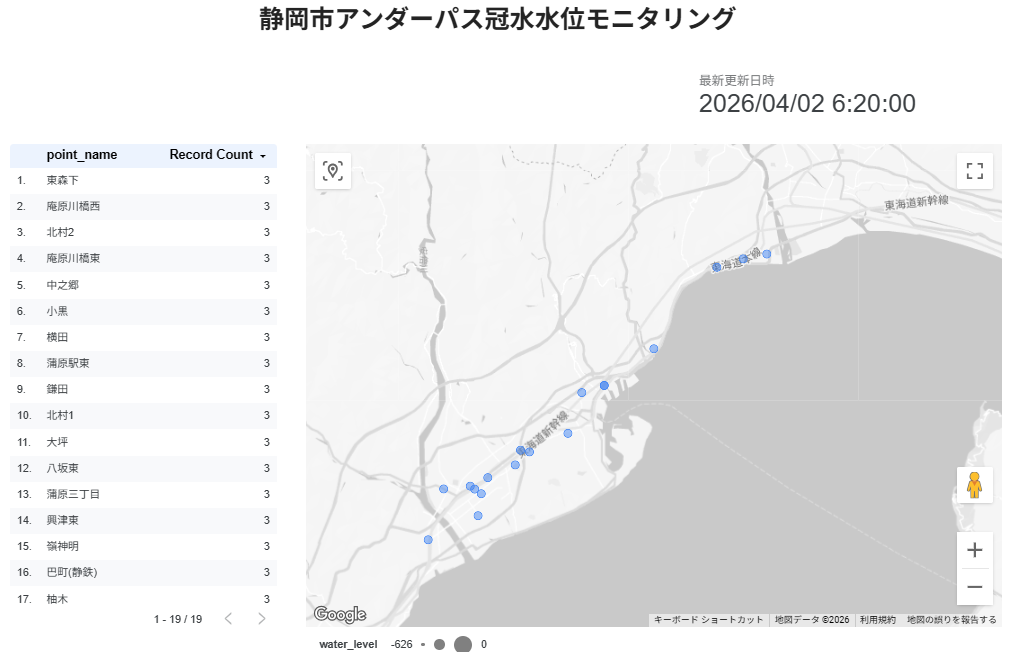
データは単なる無機質な数字ではありません。それは、私たちが暮らす街のインフラが発している鼓動そのものです。その鼓動に自らアクセスし、可視化する仕組みを構築できました。
新しい技術に直面したとき、難しそうだと立ち止まるのではなく、まずは小さく試してみる。
その試行錯誤のプロセス自体が、次もまた新しいものを作ってみたいという自発的な熱量を生み出してくれます。
皆さんもぜひ、身近なデータ、様々な機関が公開しているオープンデータを使って、ご自身だけの仕組みづくりに挑戦してみてください。