R言語を使った分析の復習
フェーズ 1: データの準備と読み込み
フェーズ 2: データクリーニングと整形
フェーズ 3: データ集計と加工 (dplyr)
フェーズ 4: ビジュアライゼーション (ggplot2)
R言語のコンソールペインをそのままコピペしたので、改行後の位置に「+」が付いてしまいました。
1. データ準備とクリーニング
# データの読み込み
avocado <- read.csv("avocado.csv")
# 1列目(おそらくインデックス)を削除
avocado <- avocado[, -1]
## 2-2. PLUコードの列名変更
# RStudioからの出力を削除し、コードのみに
names(avocado)[names(avocado) == "X4046"] <- "Small_PLU"
names(avocado)[names(avocado) == "X4225"] <- "Large_PLU"
names(avocado)[names(avocado) == "X4770"] <- "XLarge_PLU"
## 2-3. クリーニング結果の確認
# 列名とデータ構造を確認
names(avocado)
# [実行結果] "Date" "AveragePrice" "Total.Volume" "Small_PLU" "Large_PLU" "XLarge_PLU" ...
str(avocado)
# [実行結果] 'data.frame': 18249 obs. of 13 variables: ...
# Date列を文字列型 (chr) から日付型 (Date) に変換
avocado$Date <- as.Date(avocado$Date)
# 最終的なデータ構造の確認(DateがDate型になっていることを確認)
str(avocado)
# [実行結果] $ Date: Date, format: "2015-12-27" ...
2. データ可視化(ggplot2)
# データの読み込み
avocado <- read.csv("avocado.csv")
# 1列目(おそらくインデックス)を削除
avocado <- avocado[, -1]
## 2-2. PLUコードの列名変更
# RStudioからの出力を削除し、コードのみに
names(avocado)[names(avocado) == "X4046"] <- "Small_PLU"
names(avocado)[names(avocado) == "X4225"] <- "Large_PLU"
names(avocado)[names(avocado) == "X4770"] <- "XLarge_PLU"
## 2-3. クリーニング結果の確認
# 列名とデータ構造を確認
names(avocado)
# [実行結果] "Date" "AveragePrice" "Total.Volume" "Small_PLU" "Large_PLU" "XLarge_PLU" ...
str(avocado)
# [実行結果] 'data.frame': 18249 obs. of 13 variables: ...
# Date列を文字列型 (chr) から日付型 (Date) に変換
avocado$Date <- as.Date(avocado$Date)
# 最終的なデータ構造の確認(DateがDate型になっていることを確認)
str(avocado)
# [実行結果] $ Date: Date, format: "2015-12-27" ...
2. データ可視化(ggplot2)
パッケージのインストール/読み込みを行い、基本的なグラフを作成します。
R
# パッケージのインストール(初回のみ実行)
# install.packages("ggplot2")
# パッケージの読み込み
library(ggplot2)
# 1. 平均価格の分布(hist関数)
hist(avocado$AveragePrice,
main = "アボカドの平均価格の分布", # グラフのタイトル
xlab = "平均価格 (ドル)", # x軸のラベル
col = "darkgreen", # 棒の色
border = "white") # 棒の境界線の色
# 2. 時系列折れ線グラフの作成
ggplot(avocado, aes(x = Date, y = AveragePrice)) +
geom_line(color = "darkred") +
labs(title = "アボカドの平均価格の推移",
x = "日付",
y = "平均価格 (ドル)") +
theme_minimal() # シンプルなテーマを適用
# 3. 種類 (type) 別に色分けしたヒストグラムの作成
ggplot(avocado, aes(x = AveragePrice, fill = type)) +
geom_histogram(binwidth = 0.1, position = "identity", alpha = 0.6) +
labs(title = "種類別のアボカド平均価格の分布",
x = "平均価格 (ドル)",
y = "観測数") +
theme_minimal() +
scale_fill_manual(values = c("conventional" = "green4", "organic" = "orange"))
# 4. 種類 (type) 別の販売量 (Total.Volume) の比較 (ボックスプロット)
ggplot(avocado, aes(x = type, y = Total.Volume, fill = type)) +
geom_boxplot() +
labs(title = "種類別の総販売量の分布",
x = "アボカドの種類",
y = "総販売量") +
theme_minimal()3. データ集計と加工(dplyr/lubridate)
# パッケージのインストール(初回のみ実行)
# install.packages(c("dplyr", "lubridate"))
# パッケージの読み込み(ここでdplyrを読み込まないとパイプ演算子 %% が使えません)
library(dplyr)
library(lubridate) # 月次集計に必要
library(ggplot2)
# 地域の総販売量を集計し、トップ5を抽出
top_regions <- avocado %>% # %% ではなく %>% が推奨されるパイプ演算子です
group_by(region) %>%
summarise(Total_Sales = sum(Total.Volume)) %>%
arrange(desc(Total_Sales)) %>%
head(5)
# [実行結果] top_regionsが表示されます
# トップ5の地域名を変数に保存
top_5_names <- top_regions$region
# トップ5地域のデータのみを抽出
avocado_top5 <- avocado %>%
filter(region %in% top_5_names)
## 月次データへの集計
avocado_monthly <- avocado_top5 %>%
# Date列から「年」と「月」の情報を抽出して結合し、新しいMonth列を作成
mutate(Month = floor_date(Date, "month")) %>%
# Monthとregionでグループ化
group_by(Month, region) %>%
# 各月の平均価格を計算
summarise(
Avg_Price_Monthly = mean(AveragePrice),
.groups = 'drop'
)
# [実行結果] head(avocado_monthly)が表示されます
# 総合平均価格の計算
overall_avg_price <- avocado_top5 %>%
summarise(
Overall_Average_Price = mean(AveragePrice)
)
# [実行結果] overall_avg_priceが表示されます
# トップ5地域のそれぞれについて、総合平均価格を計算し、価格の高い順に並べ替え
top5_region_avg_price <- avocado_top5 %>%
group_by(region) %>%
summarise(
AveragePrice_by_Region = mean(AveragePrice)
) %>%
arrange(desc(AveragePrice_by_Region))
# [実行結果] top5_region_avg_priceが表示されます4. 高度な可視化
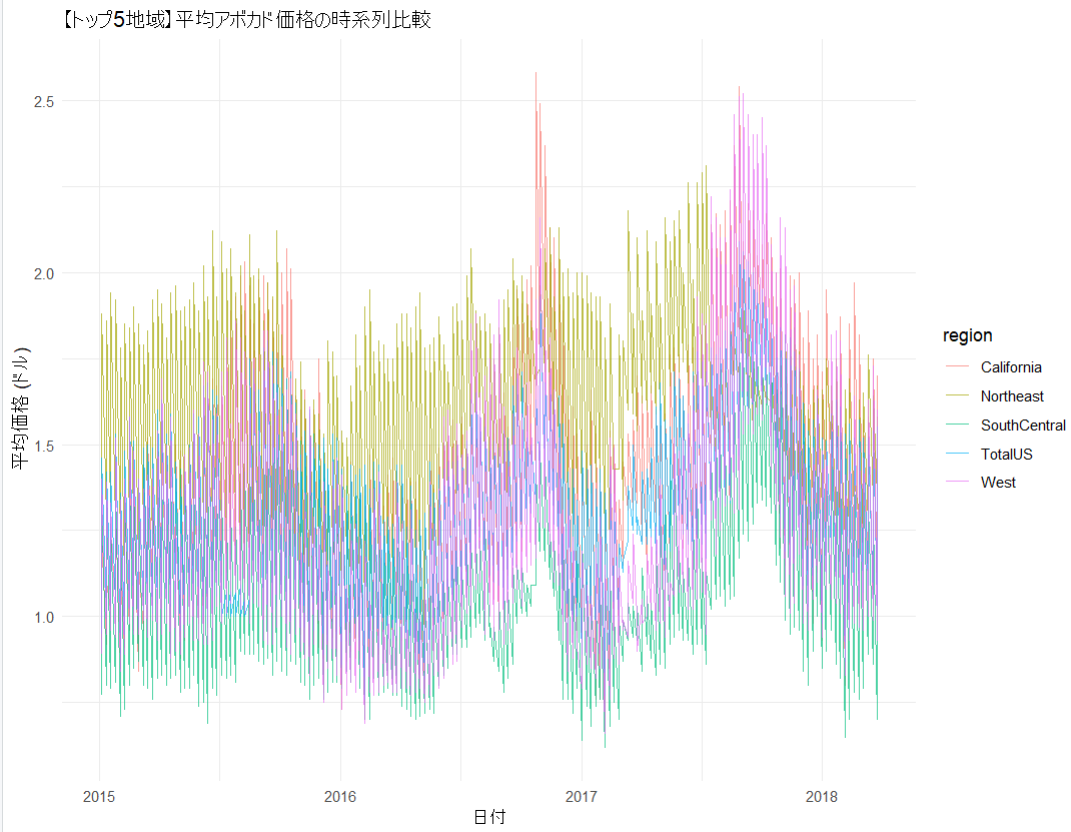
# 1. 月次データを使った価格推移グラフ
ggplot(avocado_monthly, aes(x = Month, y = Avg_Price_Monthly, color = region)) +
geom_line(linewidth = 1) + # 線を太くして見やすくします
labs(title = "【トップ5地域】平均価格の月次トレンド比較",
x = "日付 (月次)",
y = "平均価格 (ドル)") +
theme_minimal()
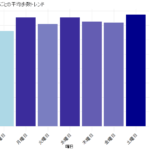
# 2. 地域の平均価格を比較する棒グラフの作成
# 棒グラフが並べ替えた順になるように、地域 (region) を因子レベルの順に設定
# arrange()で並べ替えた順番をそのまま利用します
top5_region_avg_price$region <- factor(top5_region_avg_price$region,
levels = top5_region_avg_price$region)
ggplot(top5_region_avg_price,
aes(x = region, y = AveragePrice_by_Region, fill = AveragePrice_by_Region)) +
geom_bar(stat = "identity") + # 棒の高さに値をそのまま使用
geom_text(aes(label = sprintf("%.2f", AveragePrice_by_Region)),
vjust = -0.5,
color = "black") + # 価格ラベルを棒の上に表示
labs(title = "【トップ5地域】総合平均アボカド価格の比較",
x = "地域",
y = "平均価格 (ドル)") +
scale_fill_gradient(low = "lightgreen", high = "darkgreen") + # 価格が高いほど濃い緑に
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) # x軸のラベルを見やすく回転