
1. はじめに:分析の動機とツールの選定(論理的思考力)
1.1. なぜRとPythonのトレンドを追うのか
- データ分析市場の二大巨頭であるRとPythonの勢いを定量的に把握し、将来的な技術投資の意思決定(例:どちらの言語を学ぶか、採用するか)に役立てる。AIによって再現性のない出力を得る場合とは異なり、再現性や一貫性のある出力を得るためのクエリやコードの作成にAIを活用する。
1.2. データセット選定の理由と規模の特定
- データセット名:
bigquery-public-data.stackoverflow.posts_questions(Stack Overflowの質問ログ) - 規模の確定: 総行数 23,020,127行。
- ツールの選定理由(最重要):このデータセットは2,300万行以上という規模であり、一般的な表計算ソフト(Excel)の処理能力(約100万行)を遥かに超えます。そのため、効率的に処理し、スケーラビリティを確保できるGoogle BigQueryの採用が、データアナリストとしての最善の判断であると決定しました。
2. 技術的な挑戦と高度SQLによる解決(技術的な実行力のアピール)
2.1. 課題1:データソースのアクセス権とロケーション問題の解決
- 発生した課題: GitHubやGoogle Trendsといった他の公開データセットでは、リージョン(場所)設定やアクセス権の問題により分析が停滞した。データセットのある場所に合わせたリージョンを設定しないとエラーが出る。ビックデータのアクセス権の変更でアクセスできないなどの問題も発生した。
- 解決策: エラー解決に時間を費やす非効率を避け、アクセスが安定しており、分析目的を達成できるStack Overflowデータセットへ迅速に切り替えた。さらに、クエリ設定でデータセットの場所と一致する「US (マルチリージョン)」を指定することで問題を突破した。
2.2. 課題2:正確なデータ抽出(表計算ソフトでは不可能な処理)
- 問題点: Stack Overflowのタグデータは、
tagsカラム内にpython|pandas|numpyのように縦棒(|)で区切られた一つの文字列として保存されている。- 単純な
LIKE '%r%'では、androidやserviceといった単語に含まれる’r’を誤検知してしまう。
- 単純な
- 高度SQLによる解決(Tableauの計算フィールドでは困難な処理):データ精度の確保のため、正規表現(
REGEXP_CONTAINS) を用いて、タグの区切り文字(|)や文字列の開始/終了(^、$)を考慮した厳密なパターンマッチングを実装しました。これにより、RやPythonのタグが単独で付いている質問のみを正確に抽出できました。
3. BigQueryで実行した最終クエリと結果
3.1. 最終クエリの提示
成功したStack OverflowのSQLコード全体を掲載します。
# Stack Overflow データセットを使用した R/Python の人気度比較(最終修正版)
# 目的: 技術的な質問のトレンドから、利用者の増加傾向を測定
SELECT
# 1. データの集計キーとして年を抽出
EXTRACT(YEAR FROM creation_date) AS trend_year,
# 2. 正規表現を使用して、正確に「R」という単語(タグ)が含まれるか判定
# 解説: r'(^|\|)r(\||$)' は「先頭または|の後ろにrがあり、末尾または|の前で終わる」という意味
# これにより、'android' や 'service' の中の 'r' を誤ってカウントするのを防ぎます
SUM(CASE WHEN REGEXP_CONTAINS(tags, r'(^|\|)r(\||$)') THEN 1 ELSE 0 END) AS r_question_count,
# 3. 正規表現を使用して、正確に「Python」が含まれるか判定
SUM(CASE WHEN REGEXP_CONTAINS(tags, r'(^|\|)python(\||$)') THEN 1 ELSE 0 END) AS python_question_count
FROM
`bigquery-public-data.stackoverflow.posts_questions`
WHERE
# 4. データ量を絞り込み(直近10年分程度で十分なトレンドが見れます)
EXTRACT(YEAR FROM creation_date) >= 2014
# 5. 処理コスト最適化:R または Python を含む行だけを対象にする
AND REGEXP_CONTAINS(tags, r'(^|\|)(r|python)(\||$)')
GROUP BY
trend_year
ORDER BY
trend_year DESC;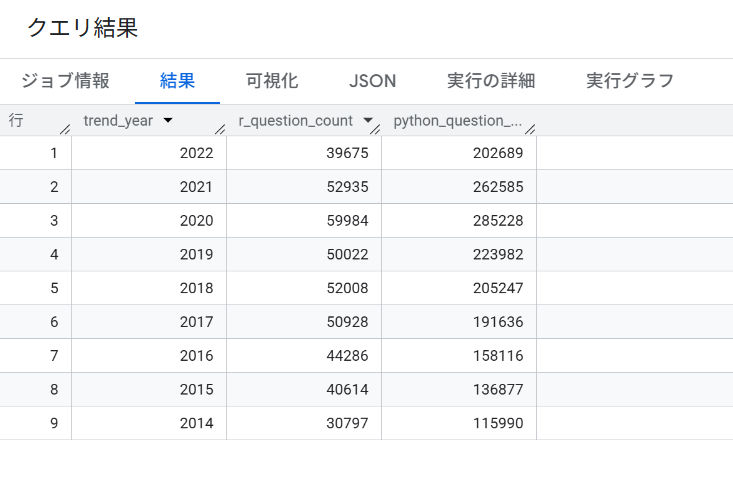
このデータをBIツール(Tableau)に渡し、「質問数の絶対量」だけでなく「前年比成長率」や「シェア率」といった意思決定に役立つ指標を可視化することで、分析を完成させます。

