はじめに:スプレッドシートから一歩先へ!直感を「事実」に変えるデータ分析
こんにちは、メンターHSです。「社会人チャンネル」へようこそ。
ビジネスの現場や後輩への指導において、「なんとなくこれが原因だろう」という直感に頼ることはありませんか?もちろん直感も大切ですが、それだけでは周囲を納得させることはできません。
一つ前のブログ記事は「スプレッドシートで実践する重回帰分析の超入門」をお届けしましたが、今回はさらにその知識を深める実践編です。
今回は、直感を「揺るぎない事実」に変える強力な武器、「重回帰分析」と「P値」について、本格的なデータ分析ツールである「R(RStudio)」を使って解説します。
表面的なツールの使い方だけでなく、クリアな思考でデータと向き合うための「裏側の理論」まで、スッキリと分かりやすくお伝えします。
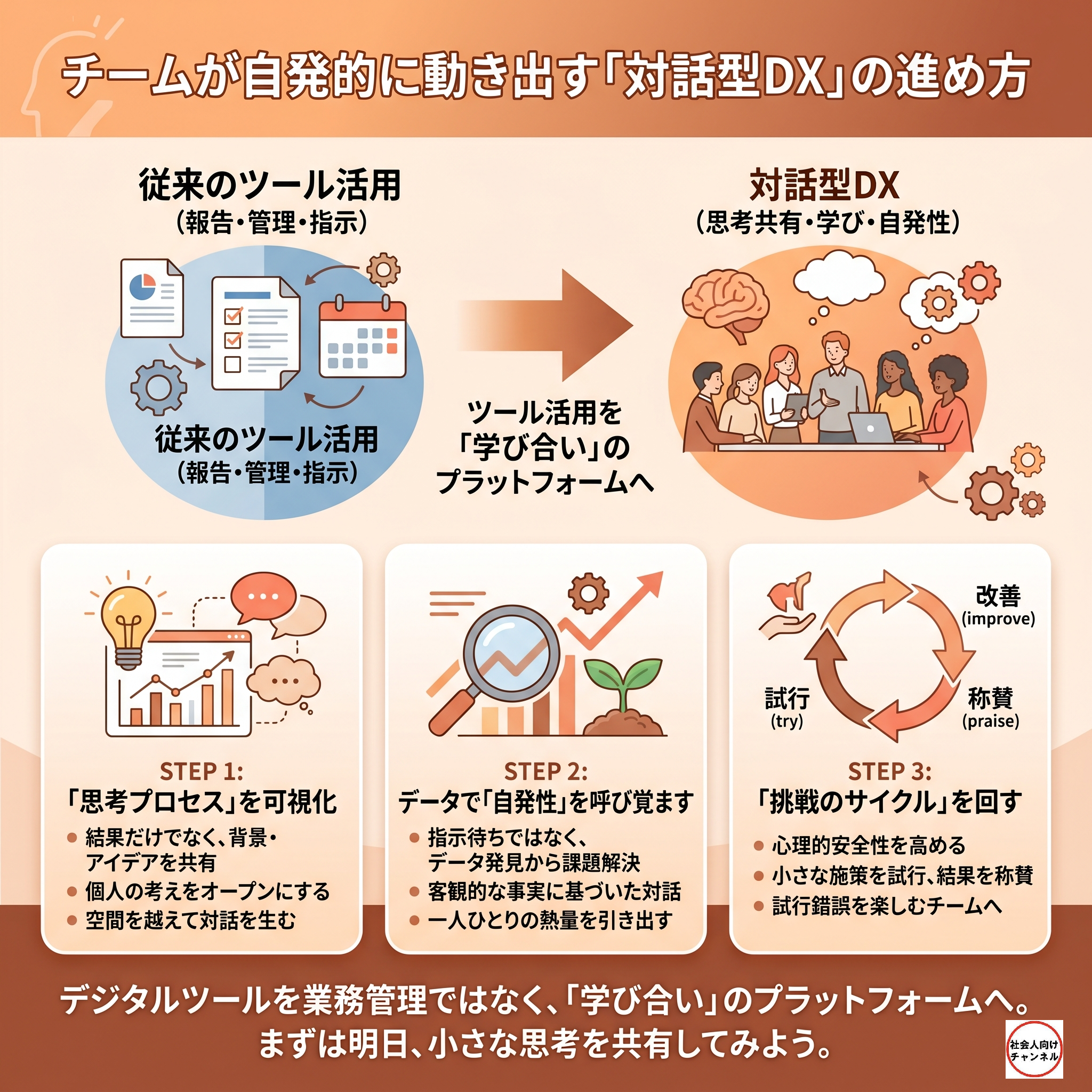
RStudioで実践!3つの原因から結果を予測する
まずは、実際にRStudioを使って手を動かし、検証した一連の流れを共有します。今回も実際の都道府県データを用いました。
(Rのコード画面)
キャプション例:ステップ1〜4まで、シンプルにコードを記述して実行します。
今回実行したのは、以下の2点です。
- 重回帰分析の実行: 「大学進学率(EnrollRate)」という結果に対して、
「所得(Income)」
「収容力(Capacity)」
「学業時間(StudyTime)」
という3つの原因が、それぞれどれくらい影響しているか予測する計算式(モデル)を作成しました。 - P値の算出: 計算された影響度が「たまたまのまぐれ」ではないかをテストしました。
正しくデータが読み込めているか、最初の数行を確認したのが以下の画面です。
(head(df_clean)の出力結果)
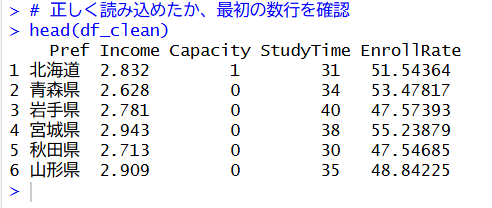
キャプション例:各都道府県のデータが、分析しやすいように英語の列名で整理されています。
英語の出力結果を解読!翻訳テーブル
分析を実行すると、画面には以下のような英語と数字の羅列が出力されます。
(summary(model)の出力結果)

キャプション例:ここから統計的な「真実」が明らかになります。
一見すると難解で戸惑うかもしれませんが、プロが見るべきポイントは決まっています。出力される専門用語を、スラスラわかる言葉に翻訳したのが以下の表です。
| Rの項目名 | 日本語の読み方 | 意味・役割(中学生レベルで解説) |
| (Intercept) | 切片(せっぺん) | 「基本料金」。もし所得や学業時間が全部ゼロでも、最低限これくらいはあるというスタート地点。 |
| Income | 所得 | 「経済力の影響」。1人当たり県民所得のこと。 |
| Capacity | 収容力 | 「環境の影響」。大学が近くにあるかどうか。 |
| StudyTime | 学業時間 | 「努力の影響」。学校外での勉強時間。 |
| Estimate | 推定値(係数) | 「影響パワー」。プラスなら「増える」、マイナスなら「減る」。 |
| Std. Error | 標準誤差 | 「ブレ幅」。この推定がどれくらいブレる可能性があるか。(今回は気にしなくてOK) |
| t value | t値 | 「証拠スコア」。この数字が大きいほど、「関係がある!」という証拠が強い。 |
| Pr(>|t|) | P値(ピーち) | 「まぐれ当たり確率」。ここが 0.05未満 なら合格!「まぐれではない」と認定される。 |
この表と、先ほどの実際の出力結果(画像3枚目)を照らし合わせることで、残酷かつ理知的な事実が見えてきます。出力結果(画像3枚目)の一番右側の「Pr(>|t|)」の列に注目してください。
- 所得(0.000944)と収容力(0.000120)は、基準の0.05を大きく下回っており、進学率に強く影響している(まぐれではない)
- 学業時間(0.363285)は0.05を上回っており、データ上はまぐれの範囲を出ない
数字は嘘をつきません。「勉強時間が長いほど進学率が高いはずだ」という思い込みを捨てて事実を受け入れることが、正しいアクションの第一歩なのです。
画面の裏側で何が起きている?統計理論の3ステップ
さて、ここからは少しレベルアップです。
ボタン一つで結果が出る便利な時代ですが、ビジネスの最前線で戦うプロフェッショナルとして「画面の見えない部分(理論理屈)」を知っておくことは非常に重要です。
P値が小さければ「まぐれではない」と判断されます。
重回帰分析において、P値を算出するためのt検定(t-test)は、「各説明変数(原因)が目的変数(結果)に対して統計的に有意な影響を与えているか」を厳密に判定するために行われます。コンピュータの裏側では、クリアな頭脳のごとく、以下の3つのステップが瞬時に計算されています。
- t値(t統計量)の算出影響パワーである「回帰係数」を、ブレ幅である「標準誤差」で割って、証拠の強さを表すt値を求めます。$t = \frac{\text{回帰係数}}{\text{標準誤差}}$
- 自由度(Degree of Freedom: df)の決定データ数($n$)と説明変数の数($k$)から、以下の式で自由度を決定します。$df = n – k – 1$
- P値(P-value)の算出算出した「t値」と「自由度」をt分布にあてはめてP値を求めます。この数字が小さいほど「まぐれではない」という重要性が高まります。
判断の目安として、P値が一般的に0.05(5%)未満であれば、「その変数は目的変数に有意な影響を与えている」と判断し、統計的に有意(Significant)であるといえます。
おわりに:圧倒的な手数で真実を導き出そう
スプレッドシートから一歩踏み出し、Rを使って一瞬でP値を導き出しましたが、その裏には精緻な統計理論が走っています。
便利なブラックボックスに頼り切るのではなく、「なぜそうなるのか?」と自ら問いを立て、理論を理解しようとする姿勢。そして、実際に何度もデータと向き合い、自らの手を動かして検証する圧倒的な手数(行動量)。
誰かに言われたからやるのではなく、真実を知りたいという純粋な熱量を持ってデータに向き合うことこそが、私たちを正しい意思決定へと導いてくれるのです。
あなたも手元のデータで、直感を事実に変える第一歩を踏み出してみましょう。
今日も最後までお読みいただきありがとうございました。