Divvy(シカゴのシェアサイクル)データを用いた分析プロセスのまとめ
1.プロジェクトの目的
会員(Member)と非会員(Casual)の利用パターンの違いを明らかにし、非会員を会員へ転換するためのマーケティング戦略につながる洞察を得る。
2.環境準備とデータの読み込み
まず、分析に必要なパッケージを読み込み、Excel形式のデータをRに取り込みます。
# ライブラリの読み込み
library(tidyverse)
library(readxl)
library(lubridate)
# データの読み込み
# 2018年Q1と2019年Q1のデータをそれぞれ読み込む
df_2018_Q1 <- read_excel("Divvy_Trips_2018_Q1.xlsx")
df_2019_Q1 <- read_excel("Divvy_Trips_2019_Q1.xlsx")3. データの結合と整理(Data Wrangling)
2つの期間のデータを1つのデータフレームに結合し、分析に必要な列を追加します。
データの結合
# 2つのデータフレームを縦に結合する
df_combined <- bind_rows(df_2018_Q1, df_2019_Q1)
# メモリ節約のため、個別のデータフレームは削除
rm(df_2018_Q1, df_2019_Q1)列の追加と型変換
分析の軸となる「利用時間」と「曜日」の列を作成します。
# 1. 利用時間 (ride_length) の計算
# 終了時刻(ended_at) - 開始時刻(started_at) で計算(単位:分)
df_combined <- df_combined %>%
mutate(ride_length = difftime(ended_at, started_at, units = "mins"))
# 計算結果を数値型(numeric)に変換
df_combined$ride_length <- as.numeric(df_combined$ride_length)
# 2. 曜日 (day_of_week) の抽出
# 開始時刻から曜日を抽出し、ラベル(Sunday, Monday...)として追加
df_combined <- df_combined %>%
mutate(day_of_week = wday(started_at, label = TRUE, abbr = FALSE))4. 分析と可視化 (Analysis & Visualization)
会員(Member)と非会員(Casual)の行動の違いを、数値とグラフで比較しました。
① 利用時間の比較
「どちらのユーザーが長く乗っているか?」を検証しました。
# 会員種別ごとの平均利用時間を集計
summary_ride_length <- df_combined %>%
group_by(member_casual) %>%
summarise(average_ride_length = mean(ride_length))
print(summary_ride_length)結果:
Casual: 約 82.6 分
Member: 約 12.9 分
可視化(棒グラフ):
ggplot(data = summary_ride_length, aes(x = member_casual, y = average_ride_length, fill = member_casual)) +
geom_col() +
labs(title = "会員種別ごとの平均利用時間", x = "会員種別", y = "平均利用時間 (分)") +
geom_text(aes(label = round(average_ride_length, 1)), vjust = -0.5) +
theme_minimal()洞察: Casualユーザーは観光やレジャー目的で長時間利用し、Memberは移動手段として短時間利用する傾向がある。
② 曜日別利用回数の比較
「いつ利用されているか?」を検証し、利用目的を推測しました。
集計と可視化コード:
# 曜日ごとの利用回数を集計
trips_by_day <- df_combined %>%
group_by(member_casual, day_of_week) %>%
summarise(number_of_trips = n(), .groups = 'drop')
# 棒グラフで可視化(dodgeで横並び比較)
ggplot(data = trips_by_day, aes(x = day_of_week, y = number_of_trips, fill = member_casual)) +
geom_col(position = "dodge") +
labs(title = "曜日別・会員種別ごとの利用回数", x = "曜日", y = "利用回数") +
theme_minimal() +
scale_y_continuous(labels = scales::comma)洞察: Casualは週末(特に日曜日)に利用が急増する一方、Memberは平日(火・水・木)の利用が多く、通勤利用が示唆される。
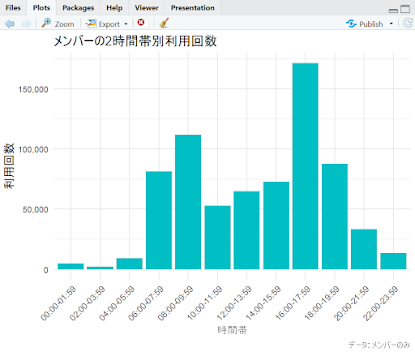
③ 時間帯別の利用分析(Memberのみ)
Memberの利用が「通勤」であることを裏付けるため、2時間ごとの利用ピークを確認しました。
分析コード:
# Memberデータを抽出し、2時間ごとの枠を作成して集計
member_trips_by_hour <- df_combined %>%
filter(member_casual == "member") %>%
mutate(
start_hour = hour(started_at),
bin_start = floor(start_hour / 2) * 2,
time_bin = paste0(sprintf("%02d:00", bin_start), "-", sprintf("%02d:59", bin_start + 1))
) %>%
group_by(time_bin) %>%
summarise(number_of_trips = n(), .groups = 'drop')
# 時間順に並べ替え
member_trips_by_hour <- member_trips_by_hour %>%
mutate(time_bin = factor(time_bin, levels = unique(time_bin[order(as.numeric(substr(time_bin, 1, 2)))])))
# グラフ化
ggplot(data = member_trips_by_hour, aes(x = time_bin, y = number_of_trips)) +
geom_col(fill = "#00BFC4") +
labs(title = "メンバーの2時間帯別利用回数", x = "時間帯", y = "利用回数") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))④ 人気ルートの特定(Memberのみ)
具体的な利用区間を特定し、車両配置などのオペレーション改善につなげる分析です。
分析コード:
# 利用回数が多いトップ10ルート(開始駅→終了駅)を抽出
top_member_routes <- df_combined %>%
filter(member_casual == "member") %>%
group_by(start_station_name, end_station_name) %>%
summarise(route_trips = n(), .groups = 'drop') %>%
arrange(desc(route_trips)) %>%
head(10)
print(top_member_routes)結論と次のステップ
Casual層: 週末・長時間利用が特徴。レジャー客向けの週末プランや観光ルート提案が有効。
Member層: 平日・通勤時間帯・短時間利用が特徴。特定の通勤ルートに需要が集中しているため、在庫管理と利便性維持が重要。
これにより、当初の目的であった「ユーザー行動の違い」が明確になり、データに基づいた戦略提案が可能になりました。
ヒロス流まとめ
データ分析に基づく戦略的提言
- データ分析の結果、非会員(Casual)は会員に比べて利用時間が約6倍も長く、主に週末のレジャー目的で利用しているという、会員とは全く異なる行動特性が明らかになりました。
- 一方で、既存会員(Member)は平日の朝夕の通勤に利用が集中しており、現在のサービスは「日常の足」として定着していますが、非会員への訴求とはニーズが乖離しています。
- したがって、非会員を会員化するためには、画一的な通勤プランを勧めるのではなく、彼らの長時間・週末利用のニーズに合わせた**「週末・観光特化型プラン」**を新たに導入することが、収益最大化への最短ルートです。